
Đã được đăng vào 03/10/2019 @ 14:59
Nhận dạng đối tượng trong ảnh bằng thư viện YOLO 3
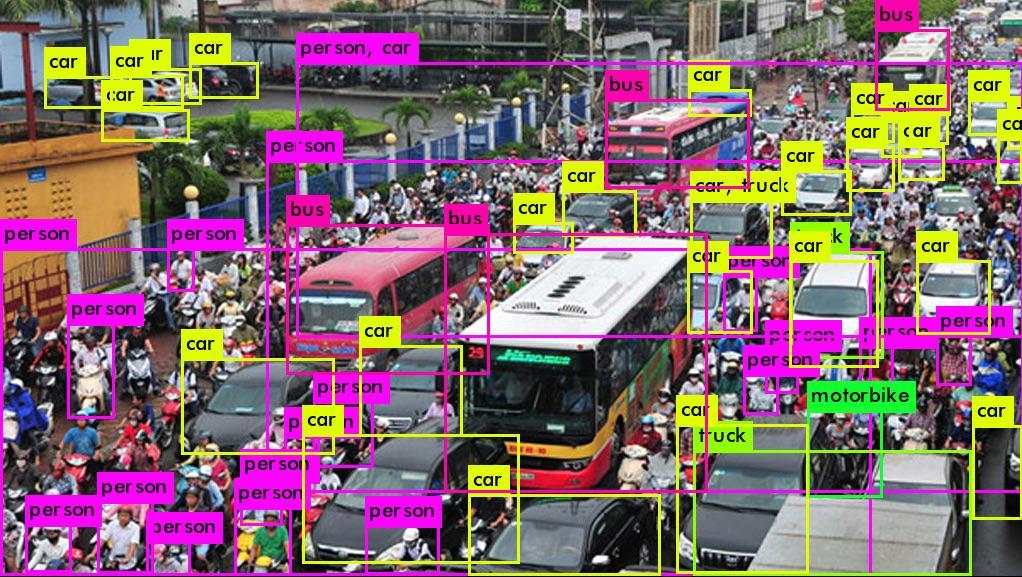
YOLO là một thư viện nhận dạng đối tượng trong ảnh hay video có tốc độ xử lý nhanh hơn rất nhiều thư viện hiện có, mức độ chính xác không phải tốt nhất nhưng ở mức tốt hợp lý trong trường hợp nhận dạng đối tượng trong video.
Bài viết này sẽ chưa đề cập đến YOLO hoạt động như thế nào, thuật toán ra làm sao mà chỉ ghi chép lại kinh nghiệm cài đặt YOLO trên Mac OSX, và nhận dạng ảnh.
YOLO có 3 phiên bản: 1, 2, 3. Ghi chú cải tiến tính năng qua các phiên bản ở đây nhé. Bài viết này sử dụng YOLO3.
Xem thêm:
- YOLO bản fork ngon hơn bản chính chủ, hỗ trợ OpenCV 4.x
- Cài đặt OpenCV nhanh nhất trên MacOSX để lập trình AI
Cài đặt căn bản không sử dụng GPU và OpenCV
Biên dịch mã nguồn
Đầu tiên là clone mã nguồn mới nhất về, không cần clone tất cả commit trước đó nên hãy thêm tham số –depth==1
Sau đó chuyển vào thư mục darknet và gõ lệnh make. Trình make dựa vào Makefile để biên dịch mã nguồn Yolo
git clone --depth=1 https://github.com/pjreddie/darknet
cd darknet
makeĐể chạy được YOLO trên máy tính (Mac, Windows, Linux, RasberryPI, Jetson Nano), chúng ta đều phải tiến hành biên dịch thư viện. YOLO có mấy lựa chọn biên dịch được cấu hình trong Makefile:
GPU=0 # Có dùng Nvidia GPU? Có là nhanh đáng kể đó
CUDNN=0 # Có tích hợp Cuda NeuralNetwork không
OPENCV=0 # Có tích hợp OpenCV không? có là thêm nhiều trò hay lắm
OPENMP=0 # Có tích hợp thư viện OpenMP của C++
DEBUG=0Để đơn giản hãy tắt hết các lựa chọn này. Quá trình biên dịch có thể xuất hiện một số lỗi, hướng dẫn xử lý lỗi tôi nói ở sau.
Giả sử lệnh make thành công, bạn sẽ biên dịch thư viện YoLo ra file binary có tên là darknet.
Sử dụng model đã huấn luyện sẵn
Yolo chỉ là framework, để nhận dạng đối tượng chúng ta cần thêm model đã được huấn luyện.
Lựa chọn đơn giản nhất là dùng lại model đã được huấn luyện sẵn, chỉ cần tải trên mạng về.
Lựa chọn hai, nếu ta phải tập trung nhận dạng một tập vật thể rất đặc thù ví dụ logo của các hãng, tên riêng các loại hoa thì sẽ phải tạo model riêng để tối ưu tốc độ nhận dạng và độ chính xác.
Hãy bắt đầu bằng dùng lại model được huấn luyện sẵn, file yolov3.weights có dung lượng khoảng 248Mb.
wget https://pjreddie.com/media/files/yolov3.weightsThử nhận dạng đối tượng trong ảnh
File ảnh đầu vào là data/dog.jpg
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpgKết quả đầu ra chó và xe đạp được nhận dạng.

Yolo nhận dạng khá chính xác những đối tượng phổ biến, được chụp ảnh chứ không phải tranh vẽ

Cũng là ảnh 2 người ôm chó – mèo, nhưng ảnh dưới là ảnh vẽ, YoLo không nhận ra được!

Chạy Yolo sử dụng Nvidia CUDA
Ở phần trên tôi dùng CPU để nhận dạng đối tượng, tốc độ rất chậm, khoảng 7 giây mới xong.
Có nghĩa để nhận dạng một phút video có 60 giây x 24 khung hình sẽ cần khoảng 60 * 24 * 7 / (60 * 60) = 2.8 tiếng !
- Hãy sửa Makefile ngay dòng đầu tiên bật GPU = 1 lên.
- Vào link này https://developer.nvidia.com/cuda-downloads để tải về CUDA tool kit, sau đó cài đặt
- Sau đó tiến hành biên dịch lại Yolo bằng lệnh make
Lỗi phát sinh khi biên dịch Yolo hỗ trợ CUDA
1- nvcc is not found. Lỗi này xuất hiện khi trình make không tìm thấy file chạy nvcc ở trong thư viện cuda mới cài ở thư mục /usr/local/cuda.
Xử lý: bổ xung đường dẫn /usr/local/cuda/bin vào biến môi trường $PATH
export PATH=/usr/local/cuda/bin:$PATH2- Lỗi biên dịch directory not found for option ‘-L/usr/local/cuda/lib64’
Nguyên nhân thư mục /usr/local/cuda/lib64 đã đổi thành /usr/local/cuda/lib
Vào Makefile sửa LDFLAGS+= -L/usr/local/cuda/lib64 -lcuda -lcudart -lcublas -lcurand
Thành LDFLAGS+= -L/usr/local/cuda/lib -lcuda -lcudart -lcublas -lcurand
3- Lỗi khi khởi động darknet “libxxx.dylib is not found”
Nguyên nhân thiếu đường dẫn hoặc biến môi trường LD_LIBRARY_PATH
Do tôi cài zsh shell cùng OhMyZSH nên tôi sửa ~/.zshrc thêm dòng này
export LD_LIBRARY_PATH=/usr/local/cuda/lib
4- Sau khi darknet đã khởi động và bắt đầu nhận dạng thì phát sinh lỗi CUDA Error: out of memory
Assertion failed: (0), function check_error, file ./src/cuda.c, line 36.
[1] 1243 abort ./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights
Lỗi này được đề cập ở đây https://github.com/pjreddie/darknet/issues/791
Cách xử lý là chỉnh file cfg/yolov3.cfg
batch=1
subdivisions=1
width=416
height=416So sánh tốc độ dùng Nvidia CUDA và không dùng Nvidia CUDA
data/dog.jpg: Predicted in 0.434673 seconds. Với tốc độ xử lý ảnh đơn như thế này khi xử lý video tốc độ nhận dạng frame per second (fps) sẽ chỉ tầm 1 đến 2 fps
truck: 92%
bicycle: 99%
dog: 99%
Không sử dụng CUDA, tốc độ chậm hơn 17 lần
data/dog.jpg: Predicted in 7.696516 seconds.
truck: 92%
bicycle: 99%
dog: 99%
Cấu hình máy tính của tôi: Dell M6800, RAM 16B, GPU: Nvidia K3100 4GRAM đời 2014. Nhìn chung là rất lạc hậu để train model phức tạp.
Nguồn: techmaster.vn

Để lại một bình luận